Analityka biznesowa z wykorzystaniem modeli uczenia maszynowego krok po kroku
Powrót do listy wpisówObecnie dane stały się jednym z najcenniejszych zasobów firm, dlatego analityka biznesowa jest kluczowa dla biznesu. Dziedzina, która się tym zajmuje, nazywa się Business Intelligence (BI). Oprócz samej analityki zawiera w sobie jeszcze dostęp do informacji oraz sprawozdawczość. Na przestrzeni lat doświadczyliśmy bardzo dużego rozwoju w tej dziedzinie, czego efektem są setki dostępnych na rynku wyspecjalizowanych narzędzi do gromadzenia i analizy danych oraz prezentacji płynących z niej wniosków. Najnowsze trendy zakładają użycie modeli uczenia maszynowego, poza tradycyjnymi narzędziami statystycznymi.
Sztuczna inteligencja w biznesie - analityka biznesowa i AI
Wykorzystanie AI w biznesie nie jest niczym nowym, ale zazwyczaj kojarzy się z optymalizacją procesów decyzyjnych (takich jak predykcja czy regresja) — rzadziej z pomocą w zrozumieniu procesów, które już zaszły. Jednak w ostatnich latach popularność zyskuje dziedzina w obrębie uczenia maszynowego, która nazywa się Explainable AI (XAI), co w wolnym tłumaczeniu można przełożyć na “wytłumaczalną sztuczną inteligencję”. W czym tkwi różnica? Tradycyjne modele pełnią rolę czarnej skrzynki, do której (po uprzednim jej wytrenowaniu) wkładamy zestaw danych i oczekujemy jakiegoś wyniku. XAI zajmuje się odkrywaniem procesów, które zachodzą w owej czarnej skrzynce, czyniąc ją przezroczystą (Glass Box). Dzięki temu jesteśmy w stanie interpretować wynik i zrozumieć, które dane miały na niego jaki wpływ.
InterpretML
Innowacją na tym polu jest najnowsza biblioteka Microsoftu dla języka Python— InterpretML. Jej algorytm jest tak skonstruowany, że końcowy model generuje łatwe do podglądu i edycji zestawienia istotności poszczególnych cech. Dzięki temu po jego wytrenowaniu otrzymujemy pełny ich przegląd oraz dodatkowo — przy predykcji — dowiadujemy się, które cechy w jaki sposób wpłynęły na decyzję modelu.
Dzięki takiemu narzędziu możemy, zadając odpowiednie pytania, uzyskać bardzo wartościowe odpowiedzi na temat naszego biznesu.
Analityka biznesowa - czego potrzebujesz?
Modele uczenia maszynowego znacznie poszerzają możliwości BI, jednak żeby w pełni je wykorzystać, musisz dodatkowo dysponować:
- zasobami programistycznymi;
- zasobami sprzętowymi.
Zasoby programistyczne mogą być własne, jeśli posiadasz taką wiedzę. W innym przypadku musisz skorzystać z pomocy specjalistów. Zasoby sprzętowe zależą przede wszystkim od danych, na jakich chcesz pracować. Na szczęście, w dzisiejszych czasach istnieje wiele sposobów na dostęp do takowych, gdzie koszty ponosi się jedynie za zużycie. W przypadku prostych zbiorów danych świetnie sprawdzi się nawet darmowa wersja Google Collab, która wspiera tworzenie notatników w języku Python.
Analiza wartości sprzedaży przy pomocy modeli — studium przypadku
Żeby nie opierać się jedynie na teoretycznych aspektach, skorzystamy z publicznie dostępnego zbioru danych dla sklepu z kawą, herbatą i akcesoriami. Zawiera on kompletną bazę danych takiego (fikcyjnego) sklepu.
Zakładamy, że chcemy odpowiedzi na pytanie: “Które produkty z dostępnego asortymentu są najbardziej wartościowe dla klientów oraz dlaczego?”. Takie odpowiedzi potencjalnie mogą pomóc nam w komunikacji z klientami, określić strategię marketingową, znaleźć luki w założeniach biznesowych, zbudować modele prognostyczne i wiele innych. Analityka biznesowa może mieć wiele zastosowań.
Plan działania
- Konfiguracja środowiska oraz załadowanie potrzebnych bibliotek.
- Załadowanie zbiorów danych.
- Przygotowanie danych.
- Określenie klastrów produktów na podstawie wartości ich sprzedaży.
- Zbudowanie modelu, który będzie umiał dopasować produkty z bazy do zdefiniowanych przez nas klastrów na podstawie cech.
- Przegląd rezultatów.
1. Konfiguracja środowiska
Jak wspomniałem wyżej, możemy wykorzystać zasoby Google Collab, aby zbudować i uruchomić nasz notebook.
import pandas as pd import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.cluster import KMeans from sklearn.metrics import accuracy_score, f1_score from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay # Biblioteki InterpretML !pip install interpret from interpret import set_visualize_provider from interpret.provider import InlineProvider from interpret.glassbox import ExplainableBoostingClassifier from interpret import show # stały parametr ziarna dla pseudo-losowych metod # gwarantuje nam przewidywalność przy ich użyciu RANDOM_SEED = 21
Będziemy korzystać głównie z biblioteki Pandas do pracy na zbiorach danych, pakietu Scikit-learn —jednej z najpopularniejszych bibliotek uczenia maszynowego w Pythonie - oraz właśnie InterpretML do zbudowania finalnego modelu (to jedyna biblioteka którą należy doinstalować ponieważ standardowo nie jest obecna w GC).
2. Załadowanie zbiorów danych
df_retail = pd.read_csv('201904 sales reciepts.csv')
df_retail.head()

df_products = pd.read_csv('product.csv')
df_products.head()
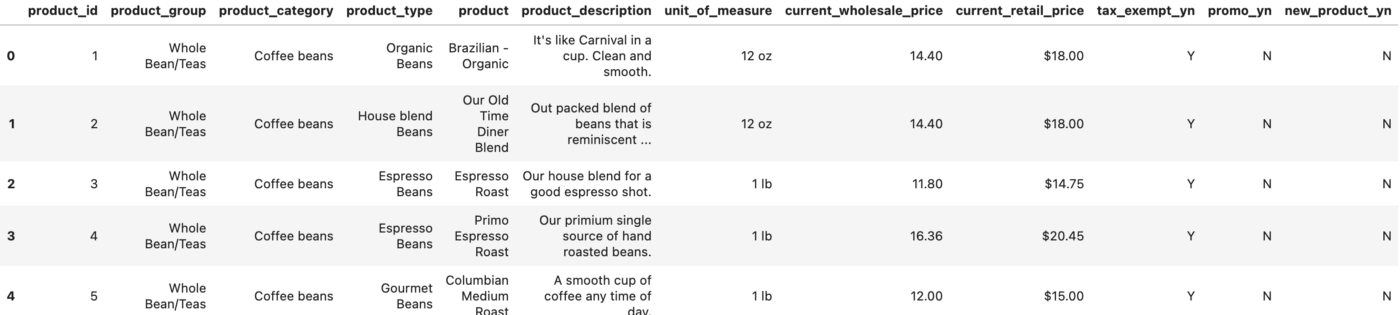
Dla przypomnienia — powyższe pliki pochodzą z Kaggle.
3. Przygotowanie danych
W przypadku każdej pracy analitycznej najważniejszy jest przegląd, a potem odpowiednie przygotowanie danych, z którymi pracujemy. Po drodze może czaić się wiele pułapek, związanych z jakością danych — mogą być niepełne, w niepoprawnym formacie, zawierać błędy. Etap sprawdzania i czyszczenia informacji jest kluczowy dla końcowego efektu, zgodnie z zasadą Garbage In — Garbage Out (śmieci na wejściu — śmieci na wyjściu).
Dla zachowania przejrzystości tego artykułu pominiemy etap weryfikacji danych i przejdziemy od razu do ich przygotowania. W pierwszej kolejności potrzebujemy zagregować dane, dotyczące wartości sprzedaży poszczególnych produktów, ponieważ właśnie ta jest naszą miarą zainteresowania.
df_retail_agg = df_retail\
.groupby(['product_id'])\
.agg(total_quantity=('quantity','sum'),total_ordered=('transaction_id','count'),total_amount=('line_item_amount','sum'))\
.reset_index()
df_retail_agg.head()
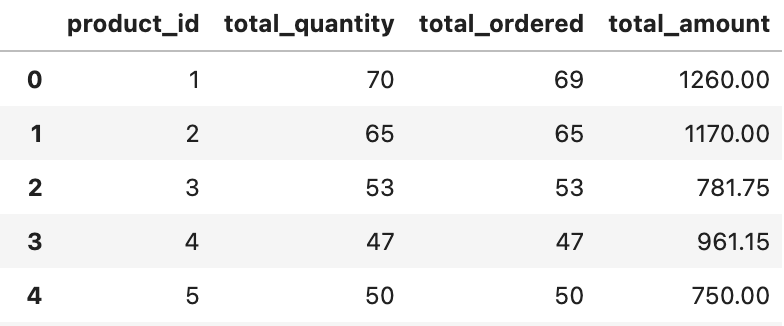
Pola w nowo utworzonym zbiorze to kolejno unikalne ID produktu w bazie, suma sprzedanych przedmiotów, suma zamówień w których wystąpił produkt, suma wartości sprzedaży. Na podstawie ID możemy połączyć wyliczone wartości sprzedaży z danymi produktu oraz uzupełnić zerami wartości dla produktów, które nigdy nie zostały kupione.
df_products = df_products.merge(df_retail_agg, on='product_id', how='left') df_products = df_products.fillna(0)
4. Określenie klastrów produktów
Żeby zbudować finalny model, musimy mieć etykiety, które określą wartość poszczególnych produktów. Możemy je uzyskać na różne sposoby — między innymi dzięki analizie RFM.
Na naszym blogu można znaleźć czym jest analiza RFM oraz jak ją zastosować. Tamten tekst skupiał się na kontekście klientów, ale koncepcja RFM jest na tyle szeroka, że można zastosować ją także na innych polach. Jeśli weźmiemy pod uwagę charakterystykę sprzedaży oferowanych przez nas produktów w wybranym okresie (wolumen, wartość, częstotliwość itp), możemy za pomocą RFM, tak jak w przypadku klientów, określić kluczowe obszary naszego asortymentu. Możemy to zrobić w klasyczny sposób, licząc poszczególne percentyle, a następnie konstruować z nich odpowiednie grupy, określając te istotne dla nas.
Alternatywą jest wykorzystanie modeli z dziedziny uczenia nienadzorowanego (Unsupervised learning) tak, aby algorytm sam znalazł istotne dla niego klastry. W tym podejściu skorzystamy właśnie z tej alternatywy, wybierzemy do tego jeden z najpopularniejszych modeli tego typu, czyli K-Means, który do wykonania analizy skupień wykorzystuje średnie odległości punktów w przestrzeni.
Musimy jeszcze zdecydować, ile zdefiniujemy klastrów. W przypadku algorytmu K-Means jest to kluczowe. Istnieje na to kilka sposobów, my skorzystamy z faktu, że naszą wartość określają jedynie 3 wymiary (total_quantity, total_ordered, total_amount). Gdyby było ich więcej, istnieją sposoby na zredukowanie ich, ale odbywa się to pewnym kosztem — wtedy lepiej zastanowić się nad wyborem innej metody wyznaczania ilości klastrów.
fig = plt.figure(figsize=(10,7))
ax = fig.add_subplot(111, projection='3d')
fig.patch.set_facecolor('white')
ax.scatter(df_products['total_quantity'],
df_products['total_ordered'], df_products['total_amount'], marker="+",
s=50, cmap="RdBu")
ax.set_xlabel("total_quantity", fontsize=14)
ax.set_ylabel("total_ordered", fontsize=14)
ax.set_zlabel("total_amount", fontsize=14)
ax.legend()
plt.show()
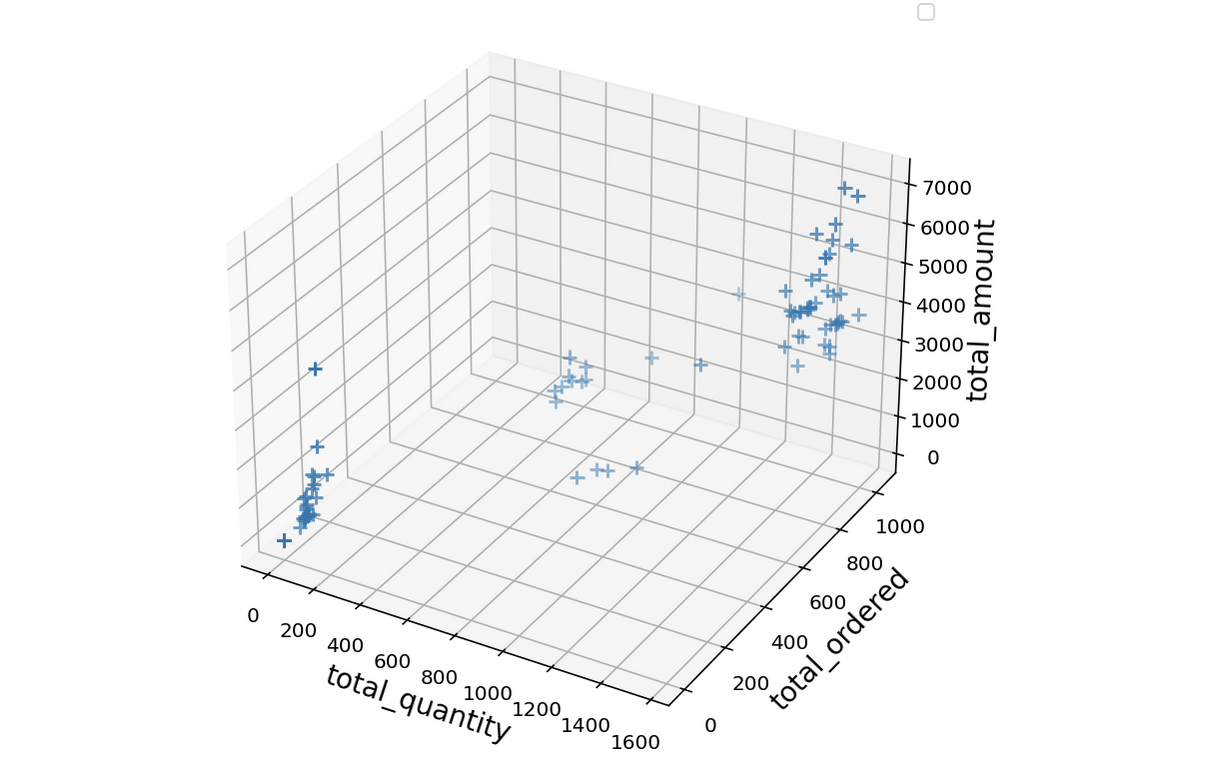
Wyraźnie widać 2 główne klastry oraz 1 lub 2 dodatkowe, które mogą być tzw. pozostałościami (outliers). Należałoby się pochylić nad tymi odstającymi elementami — istnieje kilka sposobów radzenia sobie z nimi w zależności od sytuacji. My, dla uproszczenia pozwolimy, żeby nasz algorytm dopisał te punkty do któregoś z najbliższych dwóch klastrów.
# inicjalizacja modelu
k_model = KMeans(n_clusters=2, init='k-means++', max_iter=10,
n_init=1, random_state=RANDOM_SEED)
# dopasowanie modelu do danych
k_model.fit(df_products[['total_quantity','total_ordered','total_amount']])
# przypisanie produktom określonych przez model klastrów
df_products['cluster'] = k_model.labels_
# rzut oka ma podstawową statystykę opisową naszych klastrów
df_products[['cluster','total_quantity','total_ordered','total_amount'
]].groupby('cluster').agg(['count','median','sum'])
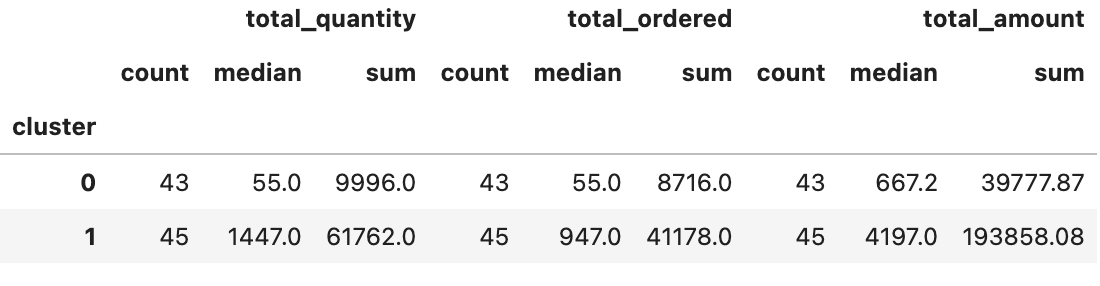
Jak widać, zagregowane wartości produktów w obrębie klastrów znacznie się od siebie różnią.. Mając zdefiniowane etykiety, możemy przejść do konstruowania modelu.
5. Budowa modelu
Zanim zaczniemy myśleć o samym modelu, najpierw musimy dokonać wyboru cech, a następnie odpowiednio je przygotować, jeśli tego wymagają. Skupimy się tylko na cechach produktu, ponieważ chcemy sprawdzić, czy istnieją wśród nich takie relacje, które determinują wysoką (bądź niską) wartość dla klientów.
Poniżej wybrałem cechy, które mogą być potencjalnie istotne dla naszego modelu.
features = ['product_group', 'product_category', 'product_type',
'unit_of_measure', 'tax_exempt_yn', 'promo_yn',
'new_product_yn']
df_products[features].head()

Cechy mogą być różnego typu — mogą być kategorialne bądź wartościami ciągłymi. W zależności od typu modelu, który stosujemy, mogą być konieczne pewne akcje, takie jak przerobienie na wartości numeryczne oraz normalizacja. W przypadku modelu, który my zastosujemy (EBM), nie jest to koniecznie. Algorytm sam dobierze odpowiedni typ cech, a potem sobie z nim poradzi. Natomiast występuje tu inny problem —dwie z cech (unit_of_measure oraz current_retail_price) przeniesione bezpośrednio do modelu zostałyby potraktowane jako wartości kategorialne, a tego nie chcemy. Musimy odpowiednio je wcześniej przygotować.
# wartość jednostki miary
df_products['n_unit_of_measure'] =
df_products['unit_of_measure'].str.extract('(\d+)', expand=False)
df_products['n_unit_of_measure'] =
df_products['n_unit_of_measure'].fillna(1)
df_products['n_unit_of_measure'] =
df_products['n_unit_of_measure'].astype('int32')
# typ jednostki miary
df_products['t_unit_of_measure'] =
df_products['unit_of_measure'].str.extract(r'([a-z ]+)', expand=False)
# cena jako liczba
df_products['current_retail_price'] =
df_products['current_retail_price'].str.extract('(\d+)', expand=False)
df_products['current_retail_price'] =
df_products['current_retail_price'].astype('float32')
# zaktualizowana lista cech
features = ['product_group', 'product_category', 'product_type',
'n_unit_of_measure', 't_unit_of_measure', 'tax_exempt_yn', '
promo_yn', 'new_product_yn']
df_products[features].head()

Jak widać, zaktualizowana lista cech jest już poprawna. Cena jest liczbą, a jednostki miar zostały rozbite na wartości i kategorie.Kolejnym bardzo ważnym krokiem jest odpowiednie podzielenie zbioru danych na zbiór do trenowania i do walidacji modelu. Sposób, w jaki to robimy, jest kluczowy. Dane nie mogą się pokrywać, a sam punkt podziału też jest istotny — w zależności od typu danych (np. tego czy są to dane zależne od czasu). W najprostszej formie dzieli się zbiór losowo na 2 części, z czego zbiór do walidacji jest z reguły tym mniejszym. Skorzystamy z pomocy metody z biblioteki scikit-learn.
X_train, X_test = train_test_split(df_products, test_size=.2, random_state=RANDOM_SEED)
Możemy przejść do trenowania modelu.
target = 'cluster' # etykieta zbioru # inicjalizacja i trenowanie modelu ebm = ExplainableBoostingClassifier(random_state=RANDOM_SEED) ebm.fit(X_train[features], X_train[target])
Proces uczenia może trwać różnie, w zależności od tego, jak duży jest nasz zbiór do trenowania oraz jakimi zasobami sprzętowymi dysponujemy. Biblioteka InterpretML nie wspiera (jeszcze) obliczeń na GPU, więc operacja trenowania może trwać długo. Trzeba natomiast pamiętać, że każdy, nawet najprostszy model uczenia maszynowego, posiada szereg dostępnych parametrów, z których zmiana każdego może być istotna w naszym przypadku. Tutaj dla uproszczenia pominiemy element tuningu naszego modelu.
# walidacja modelu
y_score = ebm.predict_proba(X_test[features])[::,1]
y_pred = y_score > .5
score = accuracy_score(y_test, y_pred)
print("Accuracy:", score)
score = f1_score(y_test, y_pred)
print("F1:", score)
print("-----------")

Podstawowe metryki do określenia jakości naszego klasyfikatora. Accuracy mówi o procencie poprawnych predykcji, jest adekwatna w przypadku zbalansowanych zbiorów danych (takich gdzie liczba danych o różnych etykietach jest podobna), w pozostałych przypadkach lepiej stosować F1.
Patrząc tylko na powyższe metryki, możemy stwierdzić, że nasz model relatywnie dobrze radzi sobie z zadaniem. Możemy też zweryfikować, jak to wygląda w poszczególnych klasach.
cm = confusion_matrix(y_test, y_pred, labels=np.unique(y_test), normalize='true') disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=['cluster_0','cluster_1'],) disp.plot(cmap=plt.cm.Blues) plt.show()
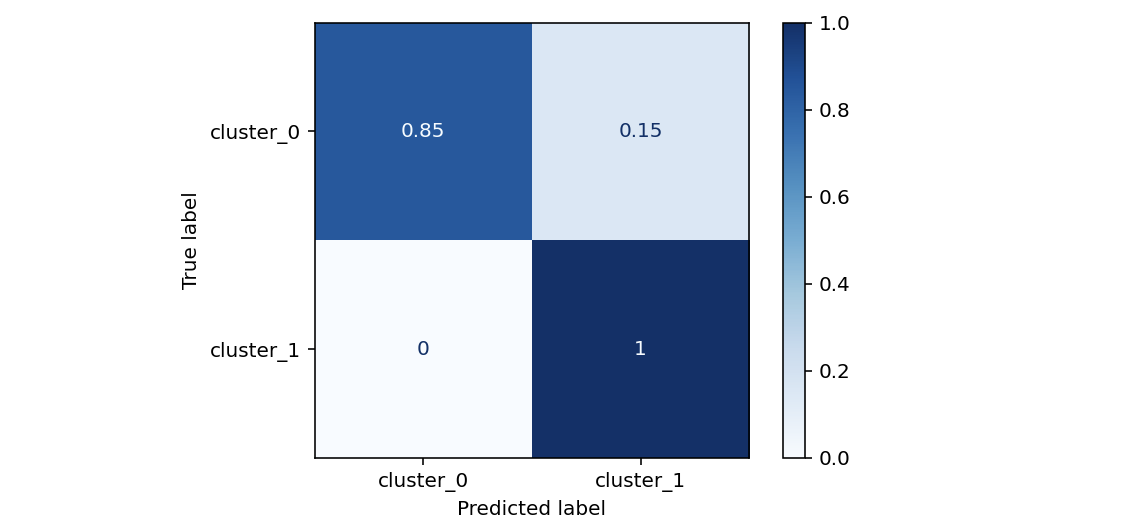
Na macierzy pomyłek (Confusion matrix) widać wyraźnie, że nasz model bardzo dobrze radzi sobie z identyfikacją klastra 1, a nieco gorzej klastra 0. Być może ma to związek z naszymi outlierami, a być może posiadamy za mało danych lub w danych jest zbyt mało informacji, które są kluczowe dla modelu. Może też istnieć jakaś anomalia, która powoduje, że z jakiegoś powodu klienci zachowują się inaczej w obrębie jakieś podgrupy produktów. Natomiast nie ulega wątpliwości, że jakość naszego modelu jest na tyle wysoka, że możemy śmiało przejść do dalszej analizy.
6. Przegląd rezultatów modelu dzięki bibliotece InterpretML
Po wszystkich tych operacjach możemy zajrzeć wreszcie do modelu i spróbować wyciągnąć jakieś wnioski na temat cech naszego asortymentu.
set_visualize_provider(InlineProvider()) ebm_global = ebm.explain_global() show(ebm_global)
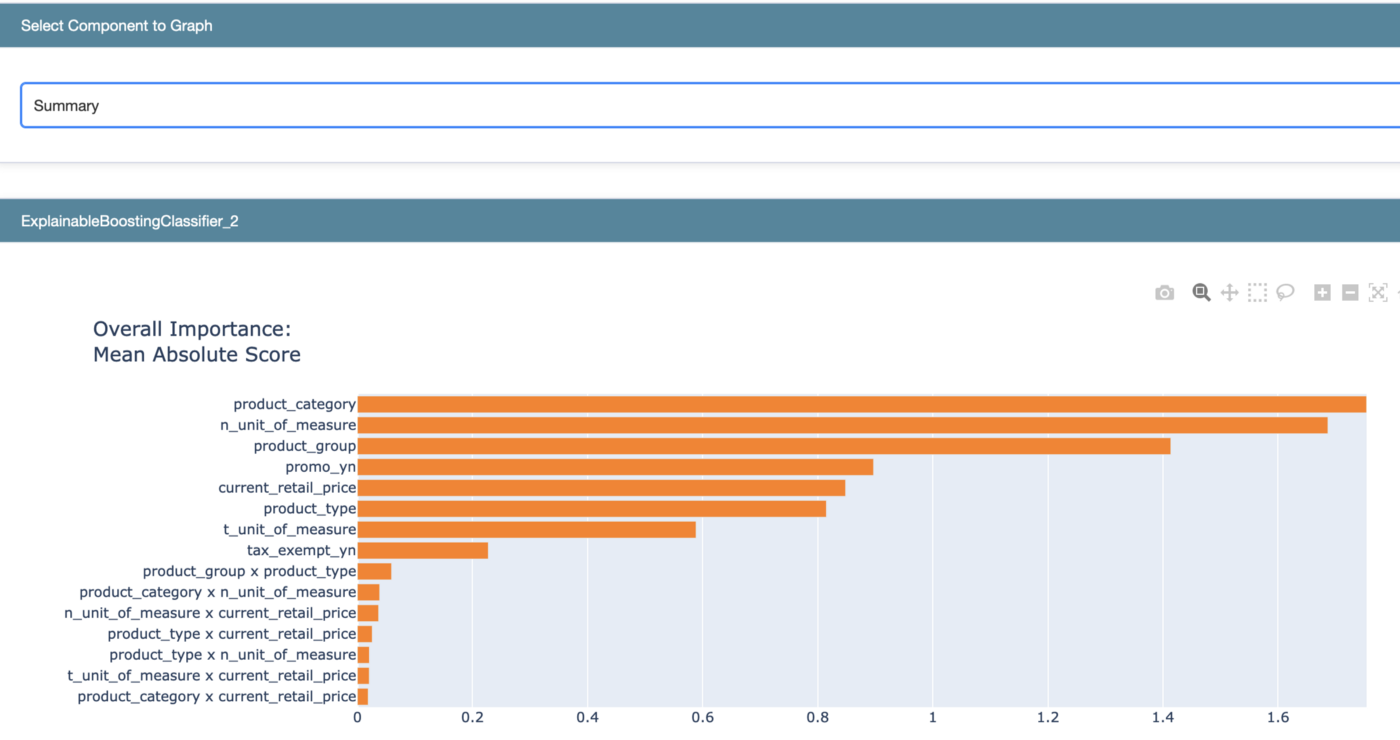
Podstawowym widokiem jest podsumowanie cech, które były dla modelu najbardziej istotne przy predykcji klasy. Pozwala ono ocenić, którym cechom warto się przyjrzeć. Rozkład istotności cech też jest ważny — w naszym przypadku żadna z cech nie dominuje nad innymi.
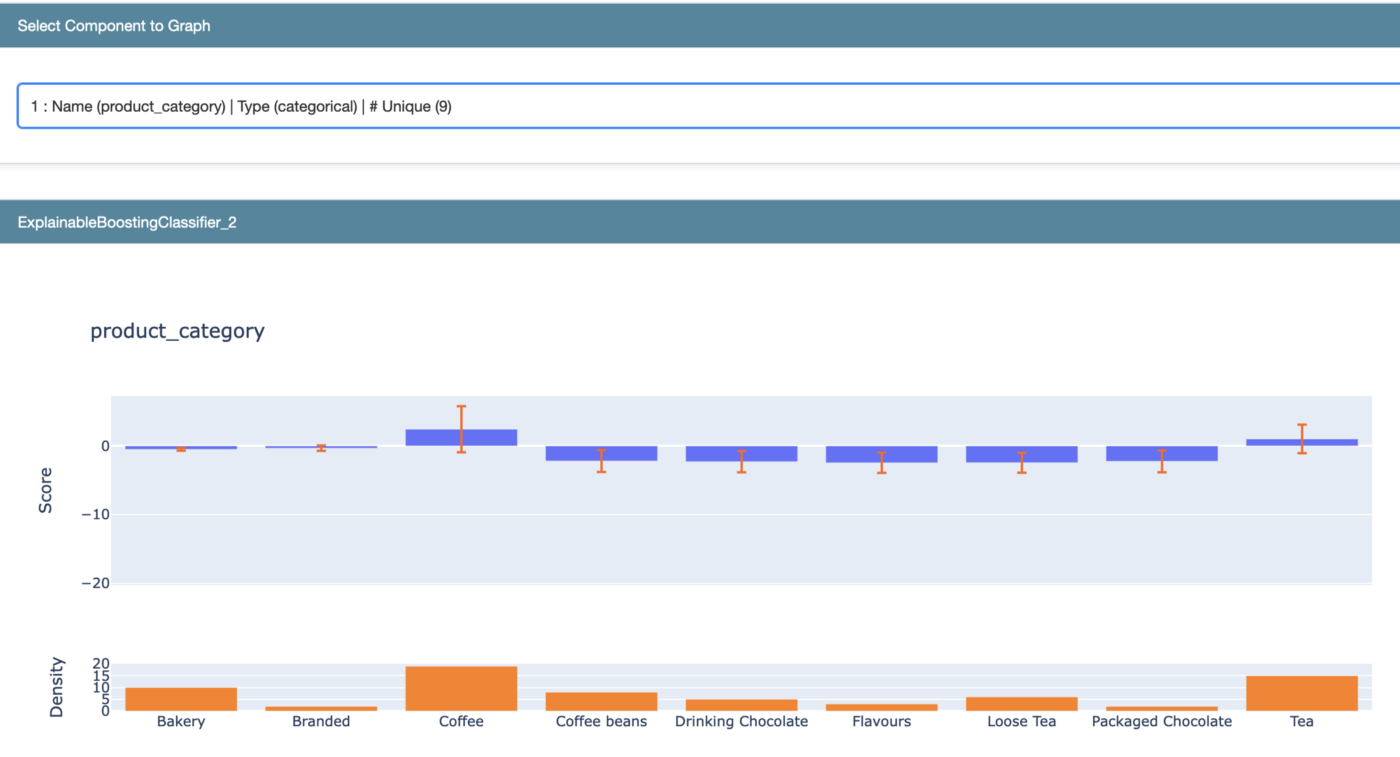
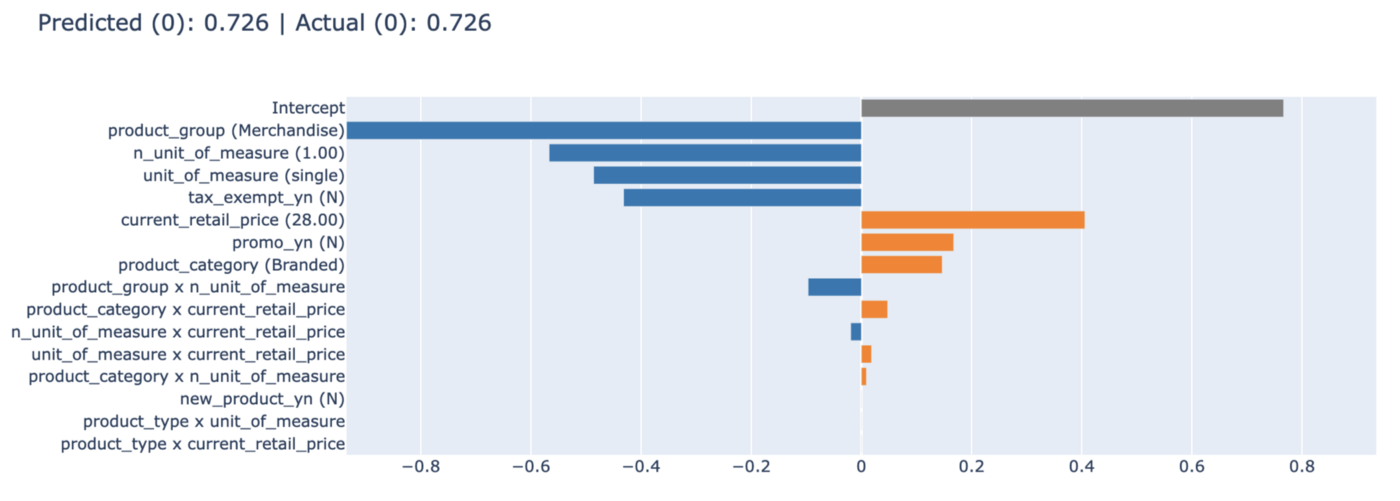
Najistotniejszą cechą, z punktu widzenia modelu, jest product_category. Jasno wskazuje ona, które kategorie produktów są bardziej pożądane przez klientów, a które wręcz odwrotnie. Score jest wartością relatywną, istotną w obrębie cechy aktualnego modelu i tak należy ją traktować. Wartości ujemne powodują, że zwiększa się prawdopodobieństwo przynależności do klastra 0, dodatnie — do klastra 1, a bliskie 0 są neutralne dla decyzji . Density określa, jak wiele w zbiorze znalazło się danych o tym typie/wartości —należy mieć to na uwadze, szczególnie jeśli jest bardzo niska.
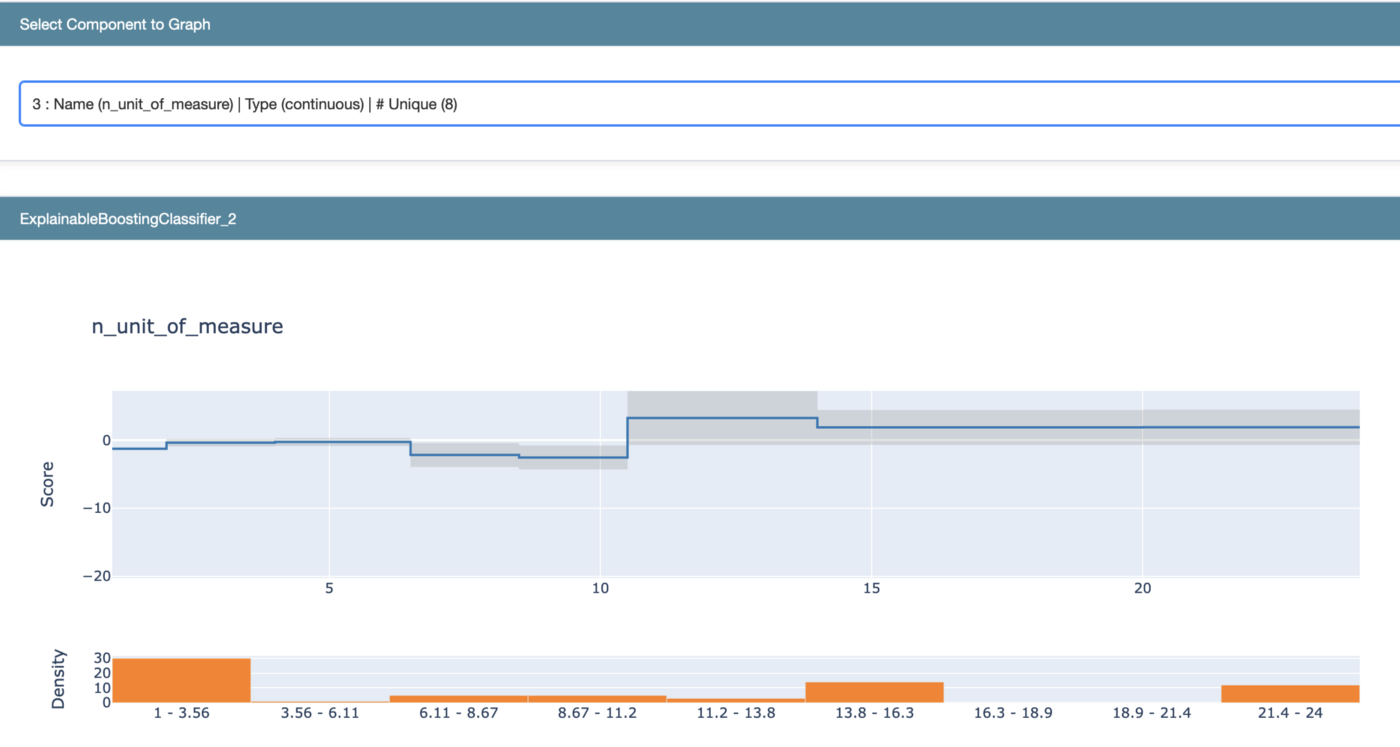
Ciekawym przykładem do analizy jest cecha n_unit_of_measure, która znalazła się w top3 pod względem istotności. W wartościach >10.5 model notuje skok prawdopodobieństwa w stronę klastra 1 (klaster ten w naszym przypadku jest tym bardziej wartościowym). Być może warto zastanowić się nad zmianą gramatury opakowania dla niektórych produktów?
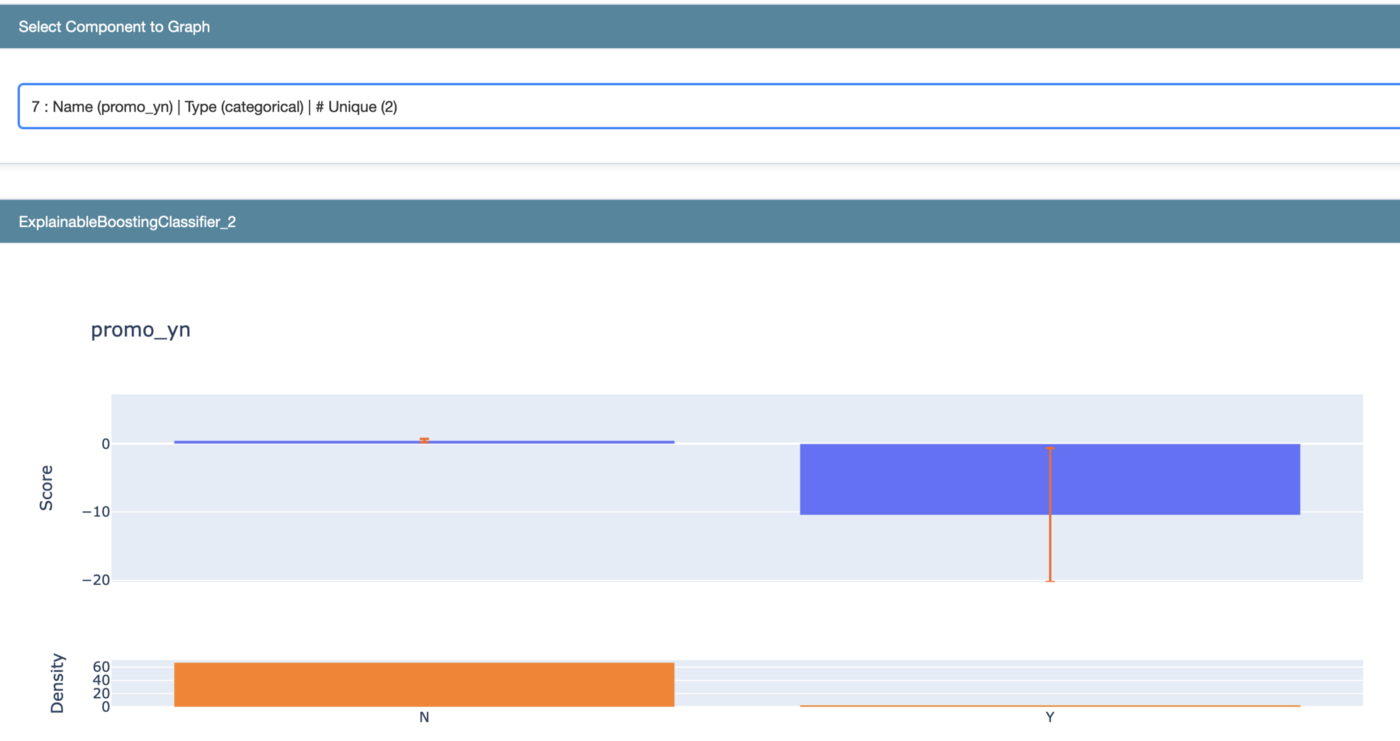
Kolejnym przypadkiem, który warto przeanalizować, są produkty objęte promocją w sklepie. Dla modelu taka kategoria drastycznie zwiększa prawdopodobieństwo przypisania produktu do klastra 0 (mało wartościowego). Być może oznacza to, że nasze działania marketingowe są nieskuteczne i warto zastanowić się nad zmianami w tym obszarze.
Model analizuje także relacje poszczególnych cech w kontekście zmiany prawdopodobieństwa w obrębie klastrów. Jednak w naszym przypadku relacje te są mało w ujęciu globalnym.
InterpretML umożliwia też analizę lokalną poszczególnych przypadków, dzięki czemu możemy zobaczyć jak wygląda wpływ wszystkich cech produktu na decyzję modelu.
ebm_local = ebm.explain_local(X_test[features], X_test[target]) show(ebm_local)
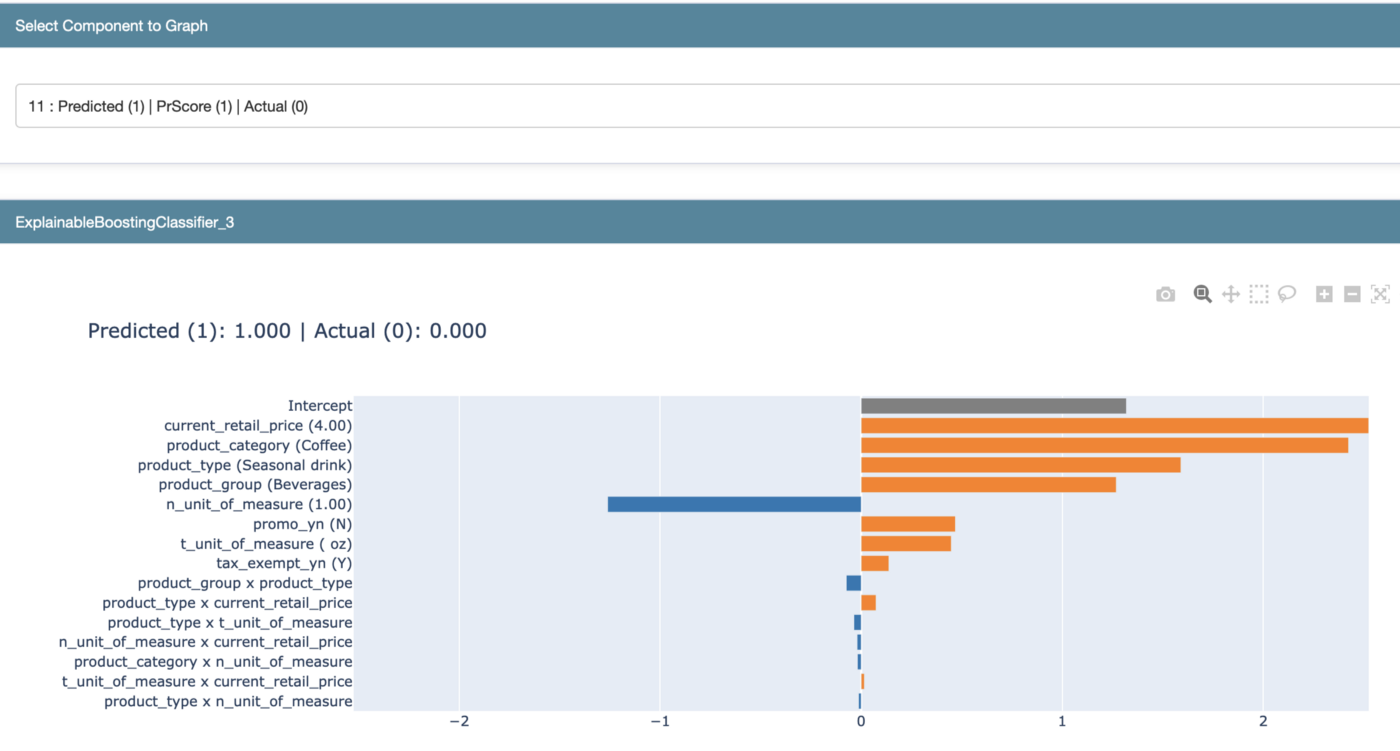
W powyższym przypadku mamy sytuację, w której klasyfikator przypisał klaster 1 ze 100% pewnością, jednak sam produkt faktycznie znajduje się w klastrze 0, czyli jest z jakiegoś powodu mało popularny wśród kupujących. Być może właśnie ten produkt powinien zostać objęty promocją?
Co dalej?
Powyższe analizy i wnioski to tylko część z możliwości, jakie stoją przed nami przy zastosowaniu uczenia maszynowego. Mając działający model o wysokiej skuteczności możemy:
- Budować weryfikowalne modele prognostyczne.
- Budować modele symulacyjne “what-if”.
- Wdrażać zmiany i szybko weryfikować nasze działania.
- Wykrywać trendy i anomalie.
Podsumowanie
Połączenie analityki biznesowej z uczeniem maszynowym, w szczególności przy użyciu technik XAI, jest potężnym narzędziem, które przy właściwym wykorzystaniu może przynieść ogromną przewagę konkurencyjną. Warto myśleć o sztucznej inteligencji nie tylko w kategoriach umiejętności przewidywania przyszłości, ale też wykorzystywania jej techniki w tym, w czym jest najlepsza — czyli rozpoznawaniu schematów. Nam zaś zostaje kreatywna część pracy, czyli wyciąganie wniosków i testowanie ich.